Electoral Calculus has pioneered regression techniques, including multi-level regression and post-stratification (MRP) methods for analysing polling data. We apply methods from mathematics, statistics, and computing to political and market research, and are recognised as a leader in this field.
Regression methods are statistical powerful tools we use to analyse polling data and they include the well-known MRP process (multi-level regression and post-stratification). These methods, which have features in common with some supervised machine learning techniques in data science, allowing us to provide clients with deeper insights and deliver more accurate results.
“Regression works by polling a set of people and asking them not just your target questions (such as voting intention) but also other facts about themselves.”
We believe in unpacking these approaches, explaining the basic principles, and helping you find the best regression techniques for your particular project, whether political or commercial.
Regression works by polling a set of people and asking them not just your target questions (such as voting intention) but also other facts about themselves. In other words, as well as gauging people's attitudes on the target question (target attitudes), the polling also gathers these other facts, known as "predictors". These can include demographic characteristics such as age, gender, location, and education as well as political characteristics like their votes in previous elections and the political alignment of their constituency. So far, this is just like conventional polling.
However, the next stage is different. Now we "regress" people's target attitudes against their predictor variables. In other words, we estimate the statistical relationship between the various predictor variables and someone's target attitude. For example, we might find that younger people are more likely to vote Labour and Green and that older people are more likely to vote Conservative and Reform. Or that someone in the south of England is more likely to prefer a particular product compared to a similar person in the north. These links are often just common sense, but the important thing is that we can quantify each relationship in numerical terms.
Finally, we apply the regression data to everyone in each area of interest (such as a constituency or district) to estimate the individual probability that the people there have a particular target attitude. For political polling, this gives an idea of how many people in each constituency support each party, from which we can work out which party is likely to win that seat. For market research purposes, it can show where people are most likely to be interested in a product or service, helping businesses target the right customers more effectively.
There are several benefits to using regression techniques over conventional polling analysis:
Considering accuracy, we have conducted many practical experiments to validate the accuracy of regression analysis over conventional polling analysis. Using a political example, regression methods out-performed conventional methods at five out of the last six UK general elections (with the other being about the same). We used the same fieldwork for each comparison, with the only difference being the type of analysis. Full details here.
Moreover, the regression also creates profiles of likely supporters of a target attitude. This can be used to inform marketing campaigns either via social media or conventional approaches.
Another key advantage is that our regression methods are accurate for very small sub-samples of the population, dramatically reducing the cost of locally focused or seat-specific polling. We can use regression to infer the likely attitudes to target question(s) by region, seat, local authority, district council ward (approximately 5,500 people), or census output area (200 people). The power of regression means that we can make these estimates without having to sample directly from each sub-population. We can estimate, for example, the attitude of people in each of the 8,800 district council wards without having to poll each ward separately. This makes local polling far quicker and more cost-effective compared to the alternatives.
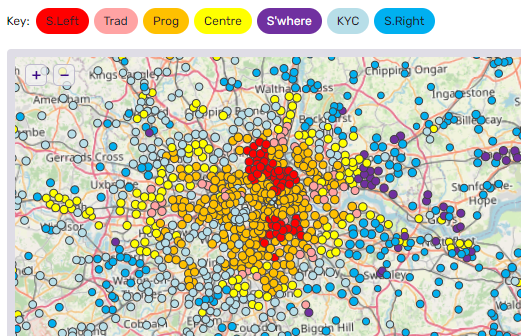
Image: Political Tribes (segmentation analysis) inferred at ward level around London.
We can apply the regression method to a wide class of target questions. This includes political questions, such as future voting intention and support or opposition for particular political statements. But we can also use it for non-political questions. These could include support or opposition for non-political statements, attitudes to commercial brands and products, or other general questions.
The main technical requirement is that the target questions must have some linkage (known as a dependency or correlation) with the predictor variables. That is to say, the target question needs to be related to the other individual characteristics that can be discovered through the poll. We are happy to advise on individual cases to assess if a particular target question is likely to be suitable.
Our regression techniques have a wide variety of uses in both political and commercial settings.
MRP started out as an innovation in electoral forecasting, and is proven to be a more accurate predictor of general elections than conventional methods. Its accuracy, affordability and seat-by-seat insight makes it a valuable tool for political campaigns of all kinds.
The most obvious application of MRP is within the context of an election, but the technique has also helped advocacy groups, think tanks and political parties coordinate strategy, test messaging and identify target groups.
The practical uses of regression extend far beyond the realm of politics. Here are just a few of the commercial applications of our MRP services:
Yes! We are happy to include additional data from the client in the regression. This is often either a proprietary database that the client maintains, or data from third-party databases, such as credit reference agencies.
We can use these additional data either to get a better regression, through an increased set of predictor variates, or we can also use them to infer likely target attitudes of sub-samples or segments of the client database population.
Not with us! Some pollsters recommend very large poll samples for regression work, which can increase the costs significantly. Electoral Calculus has pioneered cost-effective techniques for regression, making advanced polling analysis an affordable option for your business. These techniques have been extensively tested, and have been demonstrated to be as accurate as costly super-large samples.
Yes! We are also happy to work with your existing pollster (if you have one), and provide a regression analysis service on top of your existing polling. All we need is the raw polling data, and some sensible predictor questions. In many cases, it is possible to run regression analysis retrospectively on polls which you have already commissioned and studied.
We are equally happy to run new polling on your behalf.
If you have more questions or would like to check whether a potential poll is suitable for regression analysis, or get a quote for a particular project, click below to see how we could work together: